Koliko niti može biti?
Eksperimentalno programiranje.
CPU jezgra u mom računaru ima koliko i majmuna: 12. Koliko bi niti trebalo da koristimo za paralelnu obradu poslova u programu?
Jedan od saveta koji se često ponavlja je da nam ne treba više niti od ukupnog broja jezgra procesora. Ovaj savet nije netačan. Ipak, nije dovoljno precizan.
Intenzivan posao
Zamislimo nekakav intenzivan proračun koji traje par sekundi. Nazvan je “intenzivan”, jer se celokupna snaga jednog jezgra CPU koristi za posao. Na primer, takav jedan posao može biti izračunavanje decimala broja π manje efikasnim algoritmom.
Na mom računaru proračun 13000 decimala π traje koju desetinku duže od 3 sekunde (u daljem tekstu: 3s). To će biti naš intenzivan posao kojim ćemo upošljavati niti.
Odjednom ili zaredom?
Hajde da uvedimo konstantu CPU# za broj jezgra na računara. Sam broj jezgra nije važan, jer ćemo se baviti umnošcima ove konstante.
Logična je pretpostavka: CPU# jezgra mogu da obrade isto toliko intenzivnih poslova u isto vreme. Kako je u mom slučaju CPU# = 12, dakle 12 poslova mogu da se obrade u isto vreme.
Svaki posao pojedinačno traje 3s, pa će CPU# poslova da se obradi za isto 3s sekunde ukoliko ih izvršimo paralelno.
👩🔬 (Merenje.)
Rezultat merenja potvrđuje pretpostavku: CPU# poslova izvršenih u paraleli traje koliko i jedan. Tačnije - nešto duže nego samo jedan posao: 4.8s. To je OK: sistem radi još koješta, te i treba očekivati da izvestan deo vremena odlazi na thread pool, čekanje da sve niti završe posao, alociranje više memorije za toliko decimala, ali i na druge niti koje postoje u VM itd.
Idemo dalje. Hajde da povećamo broj poslova na neki umnožak N broja CPU#. Imamo dve opcije:
- da napravimo
N x CPU#niti koje sve rade u isto vreme (neograničeni thread pool, tkzv. “cached”), ili - da napravimo samo
CPU#niti koje će obrađivati poslove jedan za drugim (fiksni thread pool).
Šta će biti brže? Koji thread pool će pre završiti? Da li će neko ispasti u ovom krugu… ups, zaneo sam se malo.
👩🔬 (Merenje.)
Brzina izvršavanja je u oba slučaja ista. Povećavanjem broja niti preko broja dostupnih jezgra ne možemo ubrzati intenzivne poslove. Grafik je dosadan:
Ipak, nije sve isto.
Šta nit radi kada ne može da radi?
Hajde da izvršimo 100 x CPU# intenzivnih poslova. Izvršavanja će u oba slučaja trajati slično, kao što smo videli (izmereno oko 7.5min.)
Kada koristimo neograničeni thread pool, pravimo čak 1200 niti odjednom. Oni ne stižu da rade sve vreme. JVM dodeljuje CPU vreme nitima, pa kako ih je puno, oni prosto ne stižu da odrade posao. To izgleda ovako:
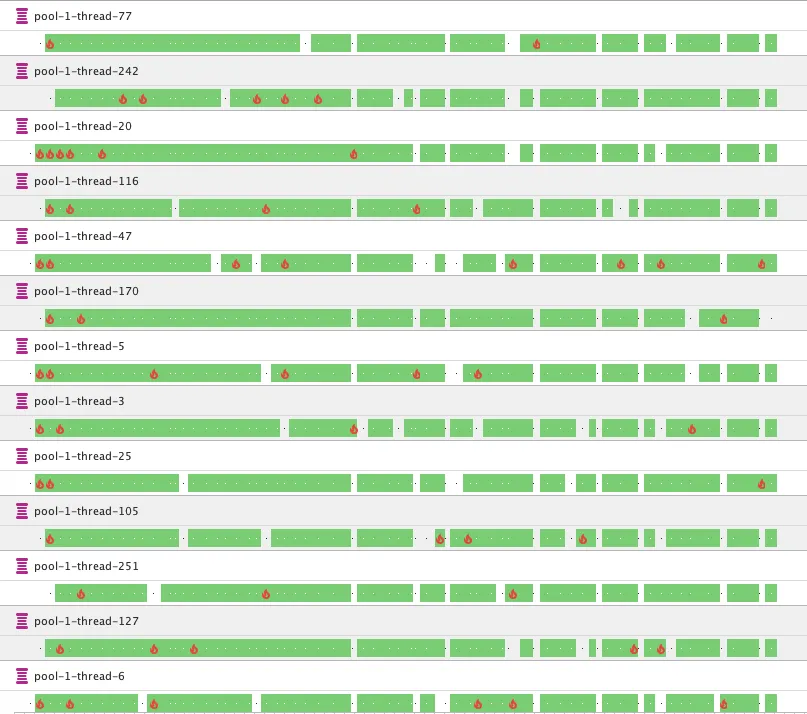
Sve niti su u RUNNABLE stanju (zeleno); pokušavaju da izvrše kod. Međutim, izvršavanje koda se dešava tek kada se niti dodeli vreme - predstavljeno vatricama na gornjoj slici. Tokom čitavog vremena između vatrica (između trenutaka kada se programski kod izvršava), nit je neupotrebljiva iako je u RUNNABLE stanju. Ovakav slučaj se naziva “izgladnjivanje” niti (thread starvation): niti se izvršavaju, ali ne prave progres.
Kada koristimo fiksan thread pool, samo CPU# (12) niti radi sve vreme punom snagom:

Razlika je opterećenje sistema. 1200 izgladnelih niti koje rade čini da preostale niti u sistemu rade podjednako sporo; jer se CPU vreme sada deli između svih niti. Dakle, samo ako intenzivan posao nije ekskluzivan za program, ovaj pristup će usporiti rad drugih delova aplikacije. Izgladnjivanje se dešava svim nitima u sistemu, ne samo ovima iz ogleda. Da ponovim, CPU vreme se deli na 100+ niti.
Kada radi samo 12 niti, to nije slučaj. One rade punom parom, ali ostaje vremena da sistem opsluži druge niti, ukoliko je potrebno. CPU vreme se deli na 12+ niti.
Koliko traje zamena niti?
Context switching je izbor aktivne niti kojoj se dodeljuje CPU vreme da odradi deo posla. Pri tome se dešava svašta nešto u sistemu; što takođe traje. Efekat je da veći broj niti znači i veći broj context switchinga, što znači i dodatno usporavanje.
Da li je zaista tako? Ako podignemo na pr. 6000 niti koje samo spavaju, da li će uticati na rad preostalog dela programa?
👩🔬 (Merenje.)
Ispostavlja se da je context switch zanemarljiv. Nisam dobio nikakvo merljivo usporenje sa uvođenjem velikog broja spavajućih niti. Sigurno da nekada ranije to nije bio slučaj; danas su procesori moćniji.
Zašto 6000 niti? Moja računar ne može da kreira, na primer, 10000 niti (postoji limiti memorije i sistema).
Šta nit radi kada ne radi?
Intenzivan posao je idealan posao. U realnom programu, veći deo vremena nit zapravo čeka: na bazu da vrati podatke, na soket da dobije odgovor. Vreme dok nit čeka je izgubljeno, neupotrebljeno vreme.
Hajde da naš idealan posao pretvorimo u realan posao: posle svakih 100 iteracija proračuna cifara π, blokiramo nit i spavamo 500ms. Time se izvršavanje od 3s produžava na nekih 55s; sada realan posao traje nekih 18 puta duže od idealnog.
Da vidimo sada kako se sistem ponaša kako povećavamo broj realnih poslova. Iste dve opcije su nam na raspolaganju: neograničeni thread pool koji pravi po nit za posao i fiksni thread pool sa CPU# alociranih niti.
Šta će raditi brže? Ko će pobediti? Ko ostaje, a ko se vraća kući… uh, opet ja.
👩🔬 (Merenje.)
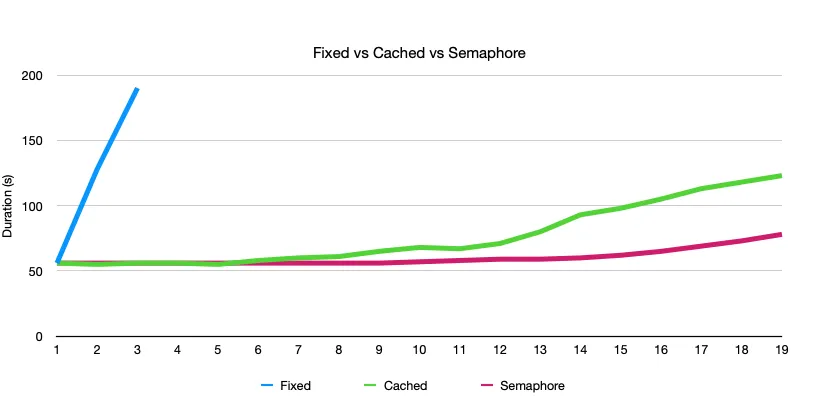
PLAVA. Fiksni thread pool sa CPU# niti u ovom ogledu ne vredi puno: izvršava poslove od 55s jedan za drugim, bez obzira što veći deo vremena niti spavaju. Vreme izvršavanja se linearno uvećava, slično prethodnom ogledu.
ZELENA. Neograničeni thread pool se sada ponaša potpuno drugačije - i pobeđuje. Pošto veći deo vremena nit spava, računar stiže da za to vreme obradi deo proračuna u drugim nitima, ako mu se ponude. Zato, na primer, sa 2 x CPU# poslova, ima sasvim dovoljno vremena da se obrade svi proračuni za vreme dok niti spavaju, tako da se ukupno vreme obrade ne menja! U periodima spavanja od 500ms jedne niti, procesor će imati sasvim dovoljno vremena da završi deo proračuna nekog drugog posla. Odnos spavanja i rada je 18:1; teoretski možemo da “naguramo” čak 18x poslova i popunimo sve periode spavanja. Zato, kako se uvećava broj niti, vreme izvršavanja se praktično ne menja, jer ima dovoljno pauza da računar obavi sve paralelne proračune.
Zašto vreme izvršavanja ipak raste kada se broj poslova uveća, primetno od x10 pa naviše? I dalje ima dovoljno pauza da se svi proračuni obave, zar ne? Zato što je izvršavanje posla stohastičko, nedeterminisano. Što je manje pauza (kako broj poslova raste), to će se više aktivnih poslova slučajno preklopiti, a kako je broj niti veliki, to će dovesti do sve češćih izgladnjivanja.
Saobraćajac za niti
Da li možemo da poboljšamo performanse? Da li možemo da uvedemo red u stohastički proces izbora posla?
Da, vrlo lako. Ustanovili smo da procesor ne može izvršavati više od CPU# idealnih poslova u isto vreme. Hajde da uvedemo semafor koji ima CPU# brojača (ili dozvola.) Takav semafor dopušta samo CPU# dozvola, ostale blokira. Hajde sada da u naš realan posao uvedemo semafor: pre spavanja otpuštamo dozvolu, a nakon spavanja zahtevamo novu.
Efekat je sledeći: iako imamo N x CPU# poslova i isto toliko niti (pošto i dalje koristimo neograničeni thread pool), dozvoljavamo samo CPU# poslova u isto vreme! Time sprečavamo izgladnjivanje niti, čime bi trebalo da ubrzamo vreme obrade.
Da li ćemo uspeti? Da li će ubrzanje biti značajno? Ili je pretpostavka pogrešna?
👩🔬 (Merenje.)
CRVENA. Kako se uvećava broj poslova, proračuni se sada pravilnije raspoređuju za vreme spavanja. Sada je garantovano da nikada ne radi više od CPU# niti u isto vreme, iako je ukupan broj niti mnogostruko veći. Rezultat govori za sebe.
Otkuda i dalje postoji blago povećanje trajanja obrade sa povećanjem poslova? Prosto, ne uspevamo apsolutno tačno napakovati poslove u periode dok nit spava.
Zanimljivo: nikada nigde nisam video da iko radi ovakvu optimizaciju.
Manje niti, manje niti
Poslednji ogled sa semaforom i dalje pati od problema viška niti. Iako samo CPU# niti radi u isto vreme (zahvaljujući semaforu) i dalje postoji nit za svaki posao. Broj niti na sistemu je limitiran, čime se ujedno ograničava ukupan broj realnih poslova koji se mogu efikasno obraditi.
Jedno rešenje je ograničavanje prethodno neograničenog thread poola. Takav pool bi imao nekakav softverski limit, a višak poslova bi se čuvao u kakvom redu.
Logično je zapitati se: ako nam samo CPU# niti radi, zašto uopšte i moramo da pravimo nit za svaki posao? Možemo li nekako pametnije da napakujemo poslove, bez da pravimo tolike niti?
Može.
Sve do sada nam je posao “spavao” (Thread.sleep()), čime je zadržavao nit za sebe - blokirao je izvršavanje niti. Hajde da promenimo ponašanje. Umesto da blokiramo nit i spavamo, mi ćemo odlagati izvršavanje (zakazivati u budućnosti). Naš realan posao se mora napisati drugačije: svaki korak posla se poziva zasebno, a trenutno stanje proračuna se prenosi između koraka posla. U slučaju našeg proračuna, potrebno je da se petlja pretvori u rekurziju.
Izmenjeni posao se sada može zakazati u novom tipu thread poola: zakazivačkom (scheduled). Reč je o nekakvom nizu poslova koji se okidaju u određenom vremenskom trenutku - a sve ih opslužuje samo jedna nit.
Da ponovim: umesto da pravimo nit za posao, mi ćemo poslove isparčati u korake koji se zakazuju unapred. Niti više ne spavaju, već se dodeljuju koracima posla. Jedan ceo posao će biti obrađen kroz više niti. Ovo je tkzv non-blocking kod, pošto eksplicitno ne blokira nit.
Smanjili smo broj ukupnih niti na samo CPU# - dok broj poslova sada može da bude proizvoljno veliki, jer se smeštaju u memorijski red.
Kakve su performanse ovakvog sistema? Da li je ovakva komplikovana promena opravdana performansama? Da li…
👩🔬 (Merenje.)
Rezultat je gotovo identičan thread poolu sa semaforima! Razlika je da sada koristimo samo CPU# niti za proizvoljan broj poslova. Lepo.
Formula
Nije dovoljno reći da je optimalan broj niti za obradu poslova jednak broju jezgra. Neophodno nam je da znamo koliko nit spava, a koliko radi. Taj odnos se naziva utilitizacija: procenat vremena koji nit provede radeći.
broj_niti = CPU# / utilitizacijaU našem ogledu, utilizacija je 1/18 = 0.054, pa je optimalan broj niti 222 što je približno 18 x CPU#.
Za razliku od gornjih ogleda, ne postoji jednostavan, deterministički način za određivanje utilitizacije. Najbolje je meriti upotrebu niti (u Javi je to moguće kroz ThreadMXBean.)
Ni ovo nije dovoljno. Bitna je i vremenska raspodela kada poslovi rade. Može se dogoditi da se svi poslovi, bez obzira na utilitizaciju, probude i počnu da rade u istom trenutku. U našem primeru, to je 222 poslova. Rezultat je izgladnjivanje niti i usporavanje.
Ilustracija: čest anti-pattern je da se značajan broj poslova zakaže za isti trenutak. Na jednom poslu je 3rd party biblioteka zakazivala stotinjak health-checkova svakih 5 sekundi. To je dovodilo do značajnog povećanja saobraćaja u internoj mreži u kratkom vremenu (spike). Ovakav anti-pattern se rešava prostim odlaganjem zakazanih poslova za neko slučajno vreme.
Formula (za blokirajuće poslove) bi mogla da bude:
max broj_niti = CPU# / utilitizacija
broj_niti koji radi u istom trenutku <= CPU#A virtuelne niti!?
Virtuelne niti su magija. Sigurno su bolje od svega!
Pa… kada je u pitanju intenzivan posao, virtuelne niti ne čine razliku - vreme izvršavanje je gotovo identično. Naravno, postoji razlika u načinu izvršavanja:
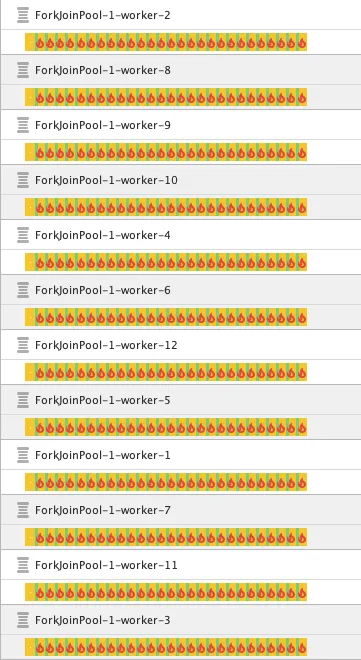
Nijedna nit ne radi sve vreme jedan posao. Niti se dodeljuju poslovima. Virtuelna nit je zapravo posao. Čim virtuelna nit/posao blokira trenutnu nit koja je izvršava, ona se “otkačinje” i stavlja u memorijski red, čime se prava nit oslobađa za drugi posao.
Dakle, virtuelne niti se bave “pakovanjem” izvršavanja paralelnih poslova u periodima dok su neki poslovi blokirani. Virtuelne niti imaju smisla za realne poslove, one koje se ne bave eksluzivno nekakvim proračunom. Hajde da vidimo kako se virtuelne niti ponašaju u drugom ogledu.
👩🔬 (Merenje.)
NARANDŽASTA. Nađite nandžarastu krivu na poslednjem grafiku. Nema je? Tu je, sakrivena ispod crvene :)
“Magija” virtuelnih niti je u tome da ne trebamo preuređivati kod, niti eksplicitno voditi računa o blokiranju niti (sa semaforima, na pr.) Utilizacija niti postaje nebitna, jer se VM sama trudi da iskoristi blokirana stanja.
Sors. Idemo dalje.